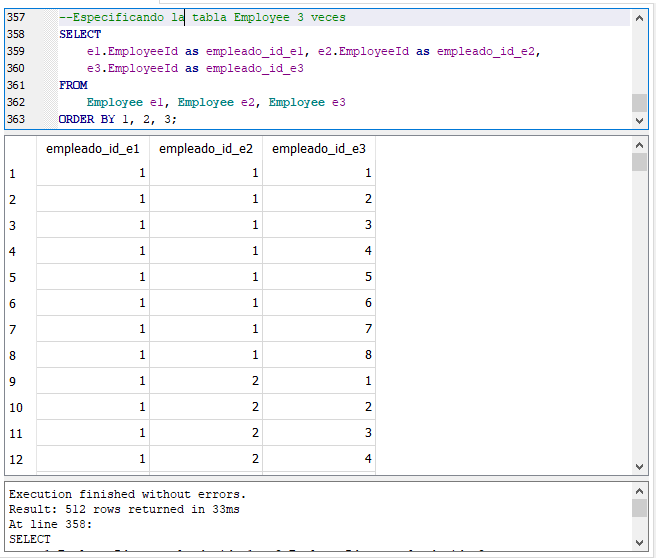
Este curso básico de SQL no pretende ser técnico, pretende ser más práctico, así que no usaré conceptos técnicos para explicar como se relacionan las tablas entre sí. Los conceptos teóricos y técnicos en diseño de base de datos, lo dejaré para un curso posterior. Lo importante aquí es cómo consultar varias tablas relacionadas entre sí.
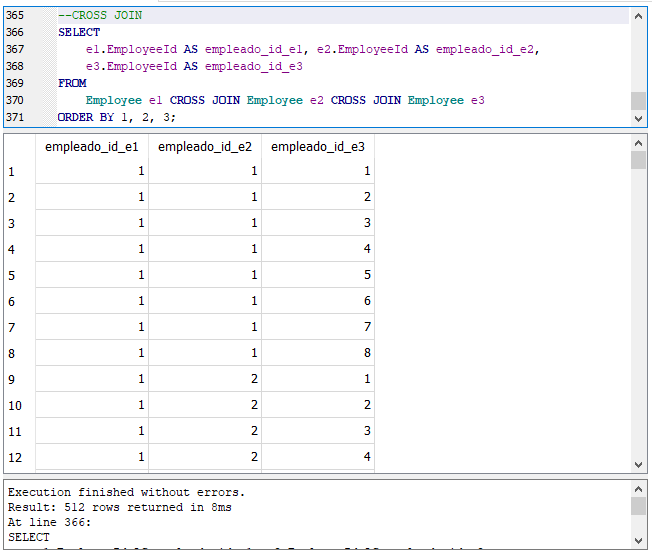
En la sección anterior vimos como consultar varias tablas separando las tablas con comas o usando la cláusula CROSS JOIN en la cláusula FROM de una sentencia SELECT lo cual tenía como resultado un producto cruzado de las filas de las tablas listadas.
Para entender el INNER JOIN necesitamos conocer como relacionar la información contenida en varias tablas dentro de una base de datos, vaya, relacional.
Relaciones entre tablas.
Para no ocupar tanto espacio o tener datos repetitivos dentro de una base de datos, cuando se diseña ésta, se opta por dividir la información en varias tablas. Pongamos un ejemplo: en la base de datos Chinook, su diseñador optó por dividir la información contenida en una factura en tres tablas: “Invoice” (factura), “InvoiceLine” (linea de factura) y “Customer” (cliente).
La primera tabla contiene los datos generales de la factura, la segunda, los datos de los artículos adquiridos pertenecientes a una factura, y la tercera, los datos del cliente que hizo la compra. ¿Y cómo se sabe que líneas de factura pertenecen a que factura y que a que cliente se hizo la factura?
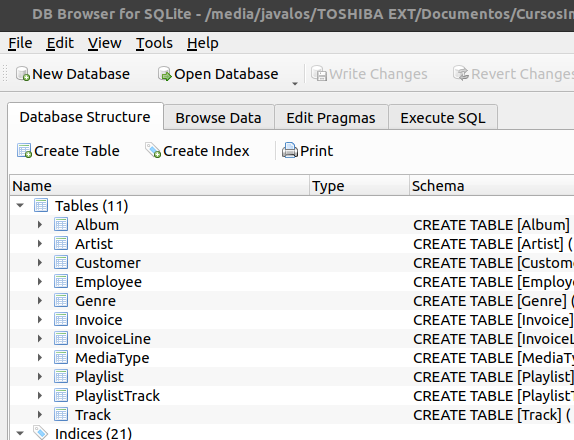
Veamos la estructura de cada tabla, es decir que columnas o campos tienen. Empecemos por la tabla “Invoice”. Para ello seleccionamos la pestaña “Database Structure” y expandimos la Sección “Tables”, si no se encuentra expandida dando clic en la flecha a su izquierda, localizamos la tabla “Invoice” en la lista de tablas y damos clic en la flecha a su izquierda para que nos muestre las columnas o campos que contiene:
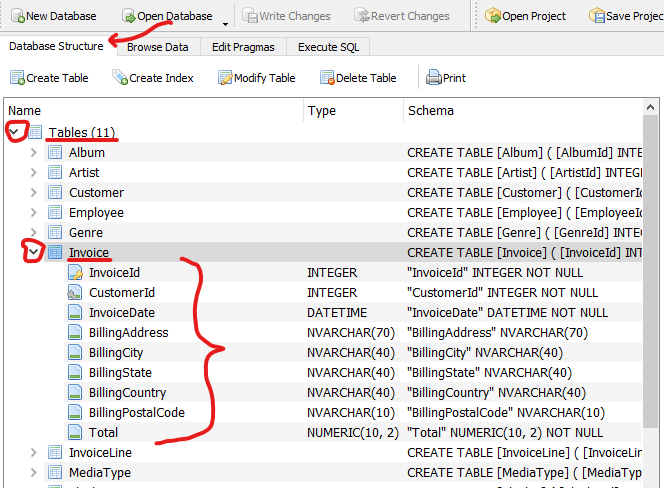
La primera columna de la tabla es “InvoiceId”, esta columna contiene un valor único, no repetible, para cada fila de la tabla. A esta columna se le conoce como el identificador de la tabla y se le suele nombrar colocando primero el nombre de la tabla, seguido por “Id” (identificador): “Invoice” + “Id” = “InvoiceId”. Asignarle el nombre con esta regla es muy común en el diseño de una base de datos. Esto para la pronta identificación del identificador. Este tipo de columnas sirven como identificador único de una fila o registro en una tabla. Se les conoce, en el diseño de una base de datos, como llave primaria o primary key. Aunque una llave primaria puede constar de una o más columnas.
En base de datos, es importante contar con un campo o combinación de campos, en cada tabla, que nos permita obtener una fila única de dicha tabla. Si esto no se cumple, se dice que la tabla esta mal diseñada. Anteriormente se optaba por asignar como identificador o llave primaria alguna columna o columnas que sabíamos que su valor iba a ser único para cada fila. Por ejemplo, para una tabla que contuviera datos de empleados, se podía optar usar su RFC o CURP (en México) como su campo identificador, ya que, en teoría, no puede haber dos personas con el mismo RFC o CURP.
Últimamente y debido a la automatización de los procesos, se ha optado por usar una columna de tipo numérico entero como su identificador uno. Este es el caso de la base de datos Chinook que estamos usando. Todas sus tablas contienen un identificador de tipo entero. Específicamente de la tabla que estamos tratando, “Invoice”, su identificador único es la columna “InvoiceId”.
La segunda columna, “CustomerId”, que por la explicación de como se nombran las columnas que actúan como identificador único, deducimos que es es un campo cuyos valores identifican una fila única en la tabla “Customer” (cliente), nos permite relacionar “Invoice” con “Customer”. Lo veremos más adelante cuando escribamos las consultas.
Las columnas restantes son datos que complementan los datos generales de la factura: fecha de la factura (“InvoiceDate”), dirección de envío (“BillingAdress”), etc.
Localizamos ahora la tabla “Customer”, que contiene la información de los clientes, y desplegamos su estructura como lo hicimos anteriormente con la tabla “Invoice”:
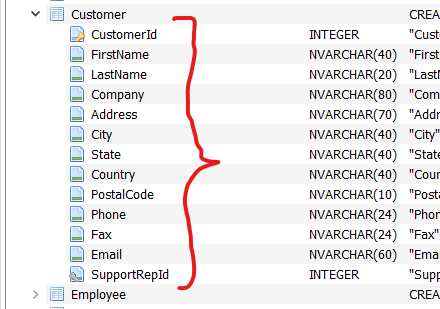
¿Cuál es el campo identificador de esta tabla? Si, “CustomerId”. Esta columna es su identificador o llave primaria. Las siguientes columnas contienen los datos generales del cliente como sus nombres (“FirstName”), apellidos (“LastName”), compañía para la que trabaja (“Company”), etc. Por último esta la columna “SupportRepId” que hace referencia a un identificador de otra tabla, es decir que se relaciona con otra tabla.
Veamos ahora la tabla “InvoiceLine”. Esta tabla contiene la información de los artículos que se adquirieron en la factura.
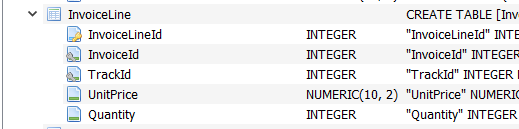
Nuevamente vemos que tiene, como las tablas anteriores, su columna identificador o llave primaria llamada “InvoiceLineId”. Vemos también que contiene el campo “InvoiceId” que relaciona esta tabla con la tabla “Invoice”. El siguiente campo o columna “TrackId” nos servirá para relacionar esta tabla con la tabla llamada “Track” que contiene la información de la pista de música.
Despliega la estructura del resto de la tablas que aparecen en la lista de tablas de la base de datos y trata de deducir cómo se relacionan las tablas entre sí.
Relacionar y consultar tablas con la cláusula Inner Join.
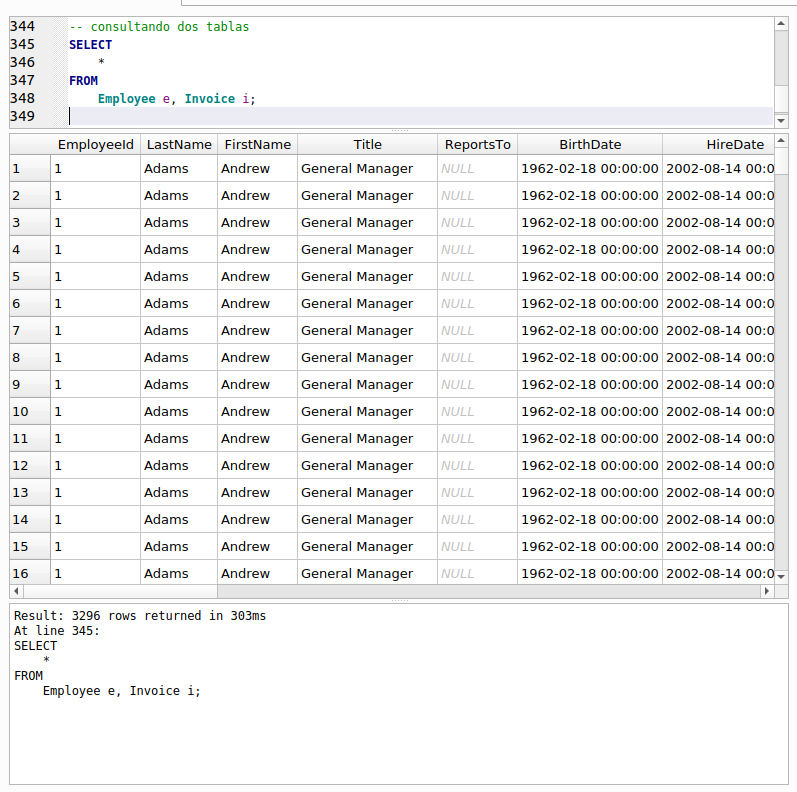
Una vez que vimos como es que se relacionan las tablas “Invoice”, “InvoiceLine” y “Customer” pasamos a hacer unas consultas que las relacionen entre sí. Primero vamos a relacionar ambas tablas como lo hicimos con CROSS JOIN y limitaremos el número de columnas a mostrar en el resultado para ver con más claridad, en un ejercicio posterior, como funciona el INNER JOIN:
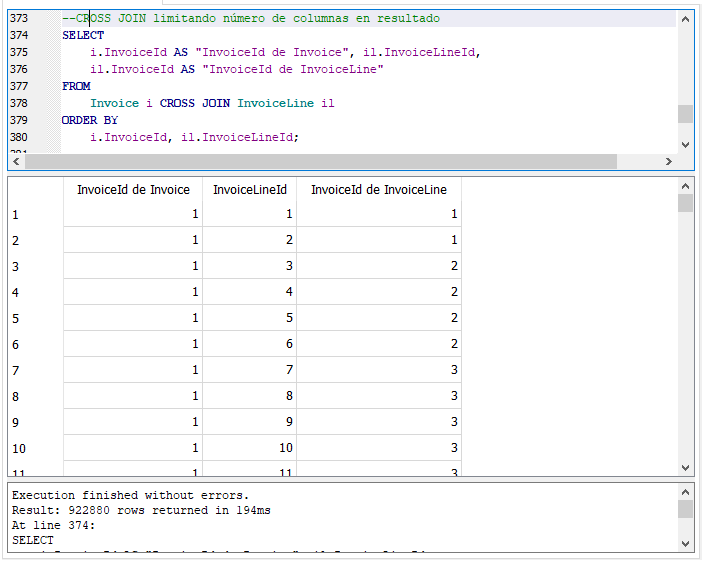
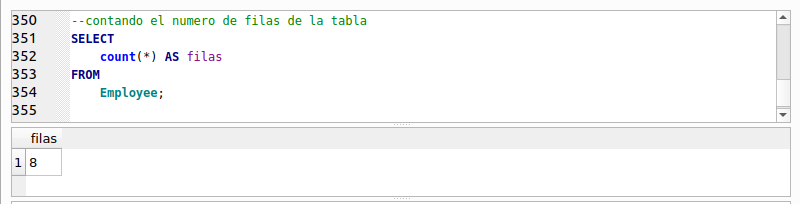
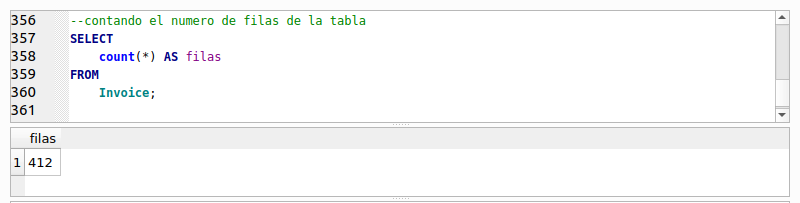
Recuerda que en lugar de la cláusula CROSS JOIN pudimos usar simplemente una coma (“,”) y hubiéramos obtenido el mismo resultado. La consulta nos da como resultado 922,880 filas, que resulta de la multiplicación de las 412 filas que contiene “Invoice” por las 2240 filas de “InvoiceLine”. Observa que cada fila de “Invoice” se combina con cada una de las filas de “InvoiceId”. La primera columna de los resultados contiene el identificador de “Invoice”, su columna “InvoiceId”, mientras que la última columna de los resultados muestra los valores de la columna “InvoiceId” de la tabla “InvoiceLine” que como vimos anteriormente indica a que factura o “Invoice” pertenece cada línea de factura, es decir a que factura se relaciona o pertenece.
Observa que en los resultados de esta consulta la fila de “Invoice” con identificador o “InvoiceId” con valor 1, se combinan con todas las filas de “InvoiceLine” sin importar si la columna “InvoiceId” de esta última tabla se relaciona o no, es decir si tienen el mismo valor o no. Vamos a modificar esta consulta para que sólo nos muestre la combinación de las filas de ambas tablas pero sólo las que se relacionan, es decir que tengan en sus campos “InvoiceId” el mismo valor:
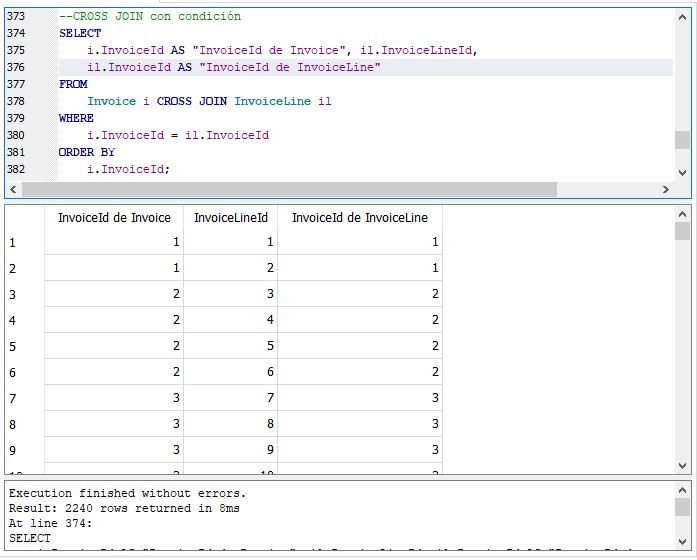
Hemos limitado los resultados de la primera consulta agregando la cláusula WHERE que ya hemos explicado anteriormente en el curso. Por cada fila que mostraba originalmente, ahora solamente nos muestra aquellas donde el valor de la columna “InvoiceId” de la tabla “Invoice” es igual al valor de la columna “InvoiceId” de la tabla “InvoiceLine”. Ahora el número de filas que regresa la consulta es de 2,240, mucho menos que las que regresaba la consulta original.
Ahora la consulta nos muestra cada factura con sus líneas de factura correspondientes. Ahora vamos a ver como obtener los mismos resultados pero empleando la cláusula INNER JOIN. Escribe y ejecuta la siguiente consulta:
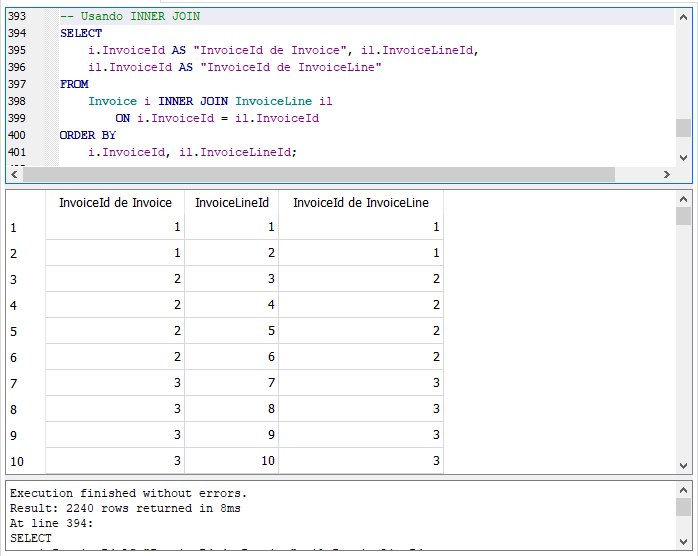
Observa que eliminamos la cláusula CROSS JOIN y la sustituimos por la cláusula INNER JOIN, así también eliminamos la cláusula WHERE pero la condición de ésta la trasladamos a la cláusula ON de INNER JOIN. El resultado es idéntico a la de la consulta anterior: el número de filas regresadas es el mismo 2,240 y sólo nos muestra las filas que cumplen la condición que hemos especificado. Si con ambas consultas obtenemos los mismos resultados ¿por qué usar INNER JOIN en lugar de CROSS JOIN o la coma (“,”)? Lo usamos para mejor claridad de la sentencia SELECT cuando unimos o relacionamos más de dos tablas.
Escribe y ejecuta la siguiente consulta donde mostramos todas las columnas de ambas tablas que se estamos relacionando o uniendo:
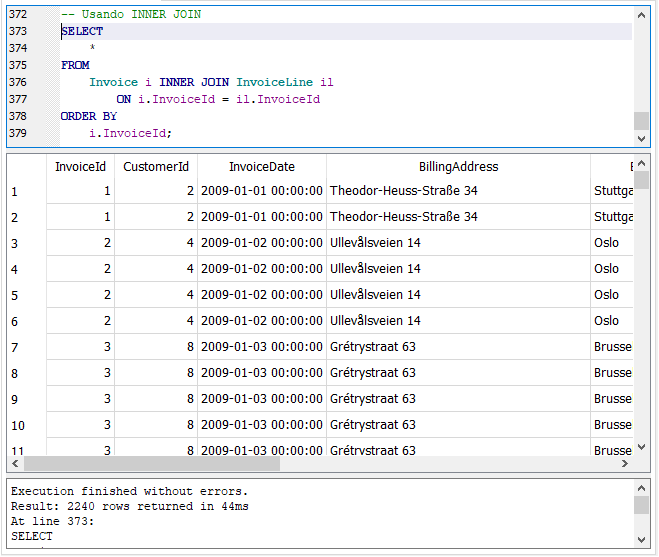
En la consulta, hemos asignado el alias “i” ala tabla “Invoice” y el alias “il” a la tabla “InvoiceLine”. La cláusula INNER JOIN se especifica dentro de la cláusula FROM de la sentencia SELECT y se coloca entre las tablas que se quieren relacionar o que tienen relación, en este caso entre las tablas “Invoice” e “InvoiceLine”. Enseguida se especifica la palabra ON y después de esta los campos o columnas por los que se va a hacer la relación, en este caso la columna “InvoiceId” de la tabla “Invoice” y la columna con el mismo nombre de la tabla “InvoiceLine”, especificando que queremos que los valores entre ambas columnas de ambas tablas sean iguales: “ON i.InvoiceId = il.InvoiceId”. Agregamos la clásula ORDER BY, para ordenar los resultados por la columna “InvoiceId” de la tabla “Invoice”.
Si observamos los resultados vemos que primero aparecen las columnas de la primera tabla que especificamos en la cláusula FROM, la tabla “Invoice” y enseguida las columnas de la tabla “InvoiceLine” que es con la que estamos relacionando la primera. Podemos observar también que filas de las columnas que pertenecen a la tabla “Invoice” en los resultados están duplicadas. Por ejemplo, en las dos primeras filas de los resultados, vemos que las columnas que pertenecen a la tabla “Invocie” tienen los mismos valores. Ambas filas tienen el identificador de la factura, es decir la columna “InvoiceId”, con valor 1 y el resto de las columnas los mismos valores en ambas filas.
Sin embargo, si nos desplazamos hacia la derecha, hasta llegar al final las columnas, veremos que los valores de las columnas que pertenecen a la tabla “InvoiceLine” no son exactamente iguales en esas dos primeras filas:
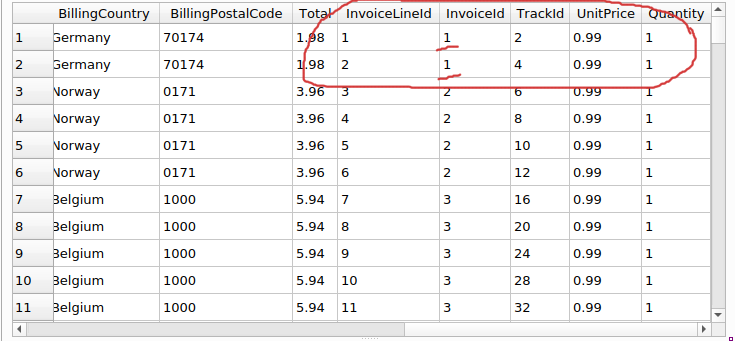
Encerradas con rojo vemos las dos primeras filas con las columnas y sus valores, pertenecientes a la tabla “InvoiceLine” o líneas de factura. Subrayados con rojo vemos los valores de la columna “InvoiceId” de esas dos filas. Vemos que tiene el valor 1. Eso indica que esas dos filas pertenecen a la factura con identificador 1, el mismo identificador que tienen los datos correspondientes a la factura (“Invoice”). Vamos a tratar de clarificar esto un poco más. Escribe y ejecuta las siguientes sentencias y observa los resultados.
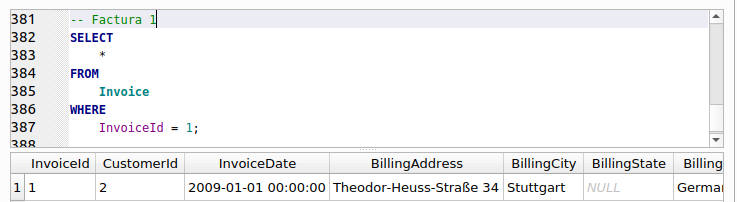
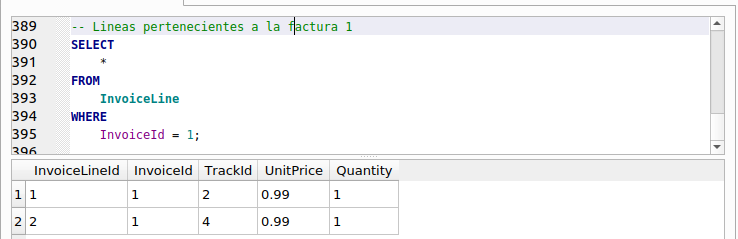
Como pueden observar, en “Invoice” sólo hay una fila que tiene su identificador, “InvoiceId”, igual a 1. Mientras que en “InvoiceLine” existen dos filas que cumplen la condición “InvoiceId = 1”. Esto significa que esas dos lineas de factura , son parte o pertenecen a la factura 1. ¿Por qué al hacer la combinación o unión de ambas tablas mediante la cláusula INNER JOIN se duplican los valores de las columnas pertenecientes a los valores de “Invoice”? Porque se cumple la condición especificada en la cláusula ON: que el valor de la columna “InvoiceId” de “Invoice” sea igual a la columna “InvoiceId” de “InvoiceLine”.
Si vuelves a revisar los resultados obtenidos con la consulta donde empleamos el INNER JOIN verás que todas las filas cumplen la condición especificada en la cláusula ON de la cláusula INNER JOIN.
Veamos un ejemplo práctico. Hemos dicho anteriormente en este curso que, ya en la práctica, es raro hacer consultas sin especificarle una condición para limitar el número de filas o registros a mostrar, sobre todo cuando las tablas contienen miles o millones de filas o registros. También en ocasiones, también limitamos las columnas a mostrar. Así que agregaremos una condición a nuestra consulta original y limitaremos las columnas a mostrar:
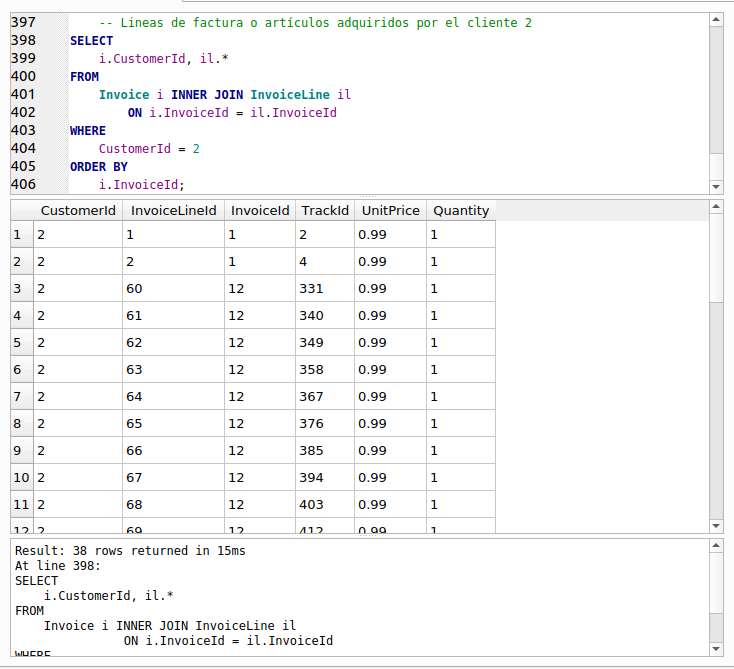
La consulta anterior asume que nos pidieron obtener todos los artículos facturados al cliente que tiene en su identificador el valor 2, “CustomerId = 2” y que muestre los resultados ordenados por el identificador de la factura, “InvoiceId”. Recuerda que los datos de los artículos facturados se encuentran en la tabla “InvoiceLine”, pero dicha tabla no contiene el identificador del cliente. La columna identificador del cliente, “CustomerId”, lo contiene “Invoice”, la factura, por lo cual es necesario hacer la unión de ambas tablas a través de la cláusula INNER JOIN para saber a que cliente pertenecen los artículos o lineas de factura comprados. Dicha unión la hacemos por medio de la columna común y que relaciona ambas tablas: el campo “InvoiceId”. Eso se lo indicamos en la cláusula ON.
Los resultados de la anterior consulta no son presentables del todo. Tenemos un identificador de cliente que nos regresa un valor numérico y un identificador de la pista de música adquirida, “TrackId”, pero no sabemos el nombre del cliente ni el nombre de la pista que adquirió.
Vamos a modificar la consulta para hacer más presentables los resultados de la misma. Escribe y ejecuta la siguiente consulta:
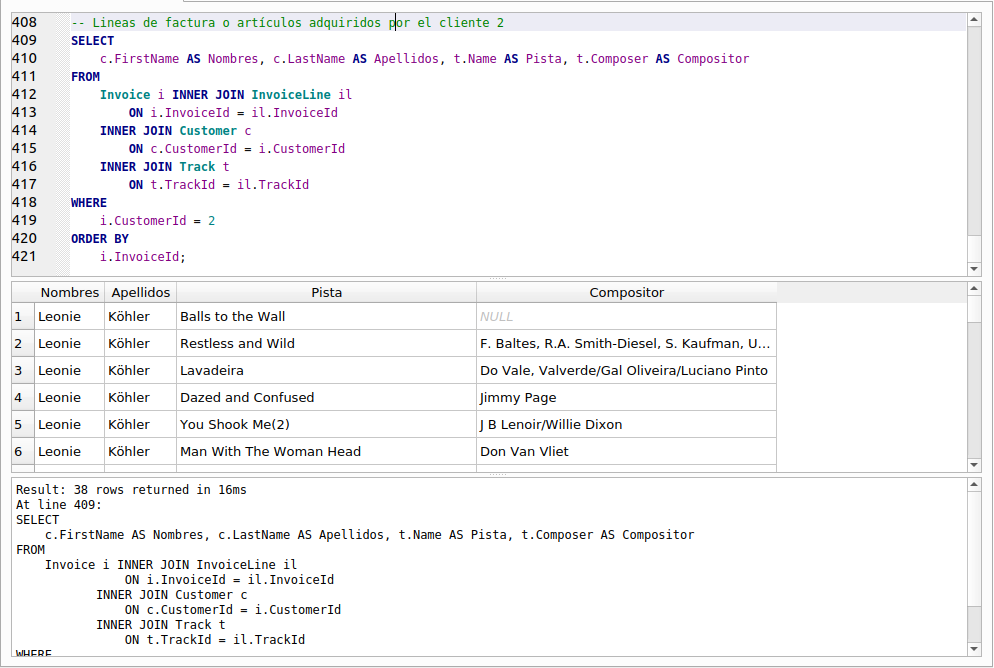
Observa la sintaxis cuando se unen varias tablas con la cláusula INNER JOIN. Las condiciones especificadas en la cláusula ON deben incluir los nombres de columnas cuyas tablas hayan sido especificadas anteriormente y la columna o columnas de la tabla especificada en el INNER JOIN. Por ejemplo, la cláusula ON del segundo INNER JOIN que especifica que vamos a unir la tabla “Customer”, la tabla que contiene los datos de los clientes y que le asignamos el alias “c”, hace referencia a la columna “i.CustomerId” que corresponde a la columna “CustomerId” de la tabla “Invoice” que anteriormente ya habíamos especificado en el primer INNER JOIN. Si en la cláusula ON especificamos un campo de una tabla que no ha sido nombrada o especificada anteriormente nos marcará error y no se ejecutará.
Como ejercicio, observa la estructura de la tabla “Track”, deduce a que tablas se relaciona observando los campos que terminan en “Id” y haz una consulta SELECT utilizando la cláusula INNER JOIN para relacionar dichas tablas.
En la siguiente sección veremos la cláusula LEFT JOIN que otro tipo de unión de tablas. ¡Hasta pronto!