Incorrect key file for table xxxxxx.MYI;try repai it.
El mensaje anterior se lo envió a un cliente al tratar de hacer un update a un campo de una tabla. Según el cliente eso le pasó después de un corte inesperado de energía eléctrica. Al parecer la tabla sufrió un daño y es necesario repararla.
Para reparar desde mysql ejecutamos la siguiente sentencia:
mysql> repair table <nombre_tabla> USE_FRM;
Donde <nombre_tabla> es el nombre de la tabla que está generando el error que coincide con el nombre del archivo llave .MYI.
Dependiendo de la cantidad de filas o registros que tiene la tabla a reparar la sentencia puede tardar un buen tiempo. La sentencia al terminar regresará dos filas indicando que la reparación fue exitosa.
Es recomendable siempre hacer respaldos diarios de la base de datos para recuperar la tabla en caso de que la sentencia no pueda reparar la tabla y poder recuperar la información desde los respaldos.
Usuario sin login (sql user without login) al restaurar un respaldo o backup de una base de datos en SQL Server 2014.
Después de restaurar un respaldo de una base de datos con otro nombre, el usuario propietario de esa base de datos, en Management Studio, mostraba el tipo de usuario como “sql user without login” por lo que era imposible conectarse a esa base de datos con ese usuario.
Para resincronizar dicho usuario después de la versión 2008 de SQL Server se utiliza el comando sql ALTER USER de la forma que se describe a continuación.
Suponiendo que el usuario nombrado “dbuser” es el usuario sin login y la base de datos restaurada es “base”, ejecutamos los siguientes comandos en una ventana de sql con un usuario administrador de la base de datos:
USE base go ALTER USER dbuser WITH LOGIN = dbuser go
Una vez hecho esto, ya debe de estar en posibilidades de hacer conexiones a la base de datos.
En la sección anterior vimos la cláusula INNER JOIN que combina dos tablas por un campo en común. En sesta sección veremos el uso de la cláusula LEFT JOIN para encontrar filas de una tabla que no tengan filas coincidentes en otra con la que se relaciona.
Revisa la estructura de las tablas “Artist” que contiene datos de los artistas y la tabla “Album” que contienen datos de los álbumes que han hecho los artistas.
Estructura de la tabla “Artist”.
Estructura de la tabla “Album”.
Como puedes observar, ambas tablas se relacionan por el campo o columna “ArtistId”. En la tabla “Artist” este campo es su identificador o llave primaria (“primary key” en inglés) , mientras que en la tabla “Album” la misma columna se le conoce como “llave foránea” (“foreign key” en inglés). Las llaves foráneas de una tabla “apuntan” a las llaves primarias de otras tablas. En la sección pasada vimos estos casos y relacionamos o combinamos las tablas por este tipo de columnas.
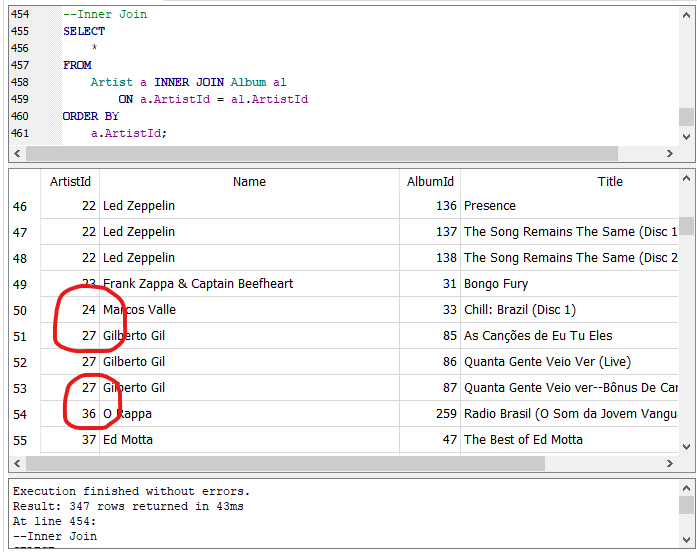
Antes de entrar de lleno al la cláusula LEFT JOIN vamos a unir ambas tablas con la cláusula INNER JOIN para destacar que cuando usamos INNER JOIN sólo obtenemos las filas de ambas tablas que tienen relación. Escribe y ejecuta la siguiente sentencia SQL:
“Inner Join” entre “Artist” y “Album”.
La consulta anterior combina o une las tablas “Artist” y “Album” mediante la columna “ArtistId” de ambas tablas siempre y cuando sus valores coincidan o sean iguales. Al final ordena los resultados por la columna “ArtistId” de “Artist”. Obtenemos 347 filas.
Deslízate hacia adelante en los resultados hasta que encuentres los registros que se muestran en la imagen anterior que muestra la consulta y los resultados. Aunque los resultados están ordenados por el identificador de la tabla “Artist”, de menor a mayor, vemos que los valores no son consecutivos, los encerrados en con rojo en la imagen. Del identificador 24 se “salta” al 27, del 27 se “salta” al 36 y así. ¿Por qué existen esos saltos? ¿No existen filas con esos identificadores en la tabla “Artist”? Estas preguntas las contestaremos con la siguiente consulta, escríbela y ejecútala:
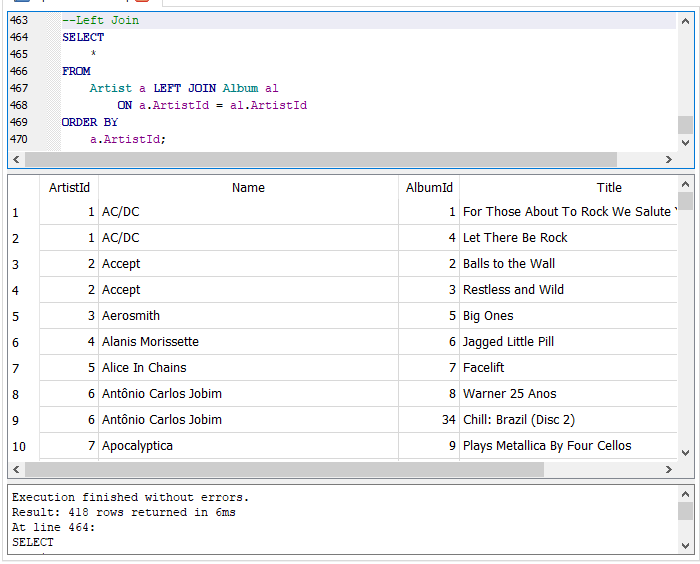
“Left Join” entre “Artist” y “Album”.
Ahora unimos ambas tablas con la cláusula LEFT JOIN y usamos la misma condición en su cláusula ON. Conservamos el orden por la columna identificador de la tabla “Artist”. Si observas ahora el resultado nos arroja más filas, 418, a diferencia de cuando aplicamos el INNER JOIN que arrojó 347.
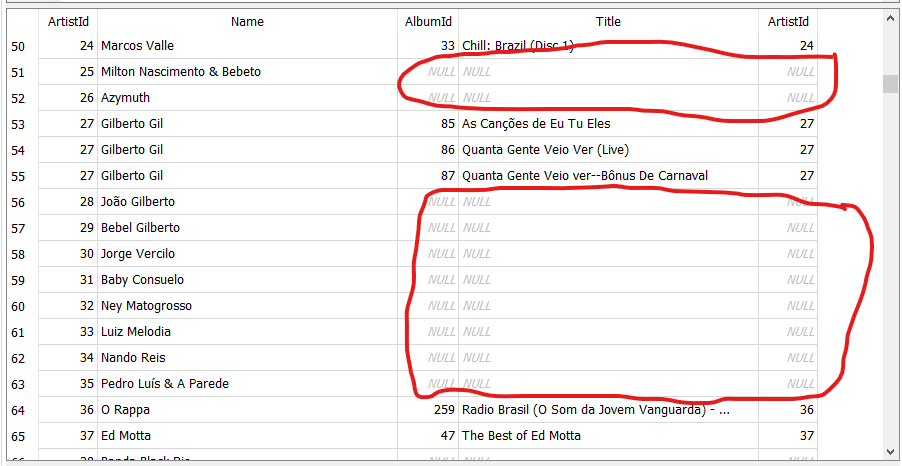
Deslízate hacia abajo en los resultados hasta ubicarte en las filas marcadas con rojo en la imagen de los resultados de la consulta que hicimos con INNER JOIN.
Resultados del “Left Join”.
Puedes observar que si existen filas en la tabla “Artist” con los valores 25, 26, 28 al 36, etc. en su columna “ArtistId” que no aparecieron en la consulta INNER JOIN que ejecutamos. También observa que las columnas de los resultados que pertenecen a la tabla “Album” no tienen valores, es decir tienen valores nulos (“NULL”). Estas columnas aparecen marcadas con rojo en la imagen.
Aquí radica la diferencia entre la cláusula INNER JOIN y LEFT JOIN, que aunque las dos unen o combinan dos tablas, INNER JOIN sólo mostrará las filas que cumplan con la condición especificada en su cláusula ON mientras que LEFT JOIN, como su nombre lo indica, mostrará todas las filas de la tabla que se encuentre a la izquierda (“left” en inglés”) cumpla o no cumpla con la condición de su cláusula ON. Si las filas de la tabla a la izquierda no tienen coincidencia con alguna fila de la tabla a la derecha de la cláusula LEFT JOIN, de todas forma aparecerán en los resultados de la consulta y las columnas pertenecientes a la tabla a la izquierda de la cláusula se rellenarán con valores nulos como observamos.
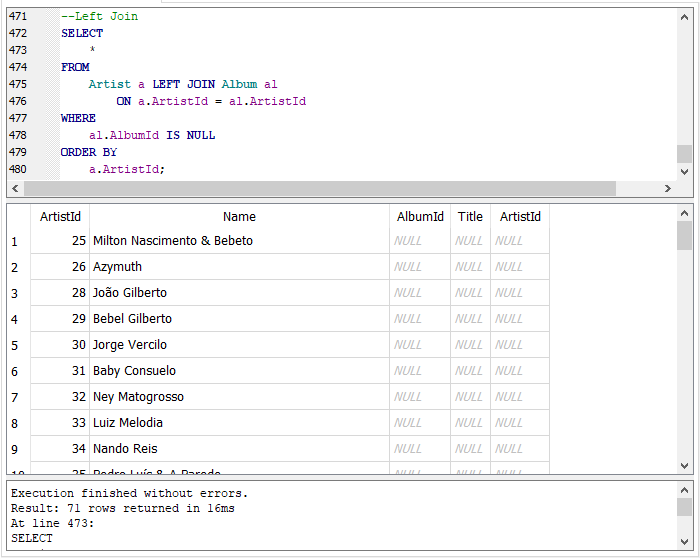
Conociendo el comportamiento de la cláusula LEFT JOIN, queremos encontrar aquellos artistas que no tenga un álbum de música asociado, es decir, las filas en la tabla “Artist” que el valor de su identificador, columna “ArtistId”, no se encuentre en la tabla “Album”. Escribe y ejecuta la siguiente sentencia SQL:
Mostrando artistas sin álbum.
Observa que a la consulta original le agregamos la cláusula WHERE para que sólo nos muestre en los resultados las filas que regrese con valor nulo en la columna “al.AlbumId”. Esto lo logramos comparando dicha columna con el operador “IS NULL”.
El operador “IS NULL” es usado cuando queremos sabe si el valor de un campo no tiene valor o esta nulo. No use el operador de comparación “=” (igual) con valores nulos.
Tomamos la columna identificador de “Album” ya que las columnas que son identificadores o llaves primarias, nunca tienen valor nulo.
Existen 71 artistas o filas que no tienen un álbum asociado en la base de datos. Como ejercicio, modifica la consulta para que sólo muestre las columnas de la tabla “Artist” ya que como vemos en los resultados de la consulta anterior las columnas de la tabla “Album” tienen todas valores nulos. ¡Hasta pronto!