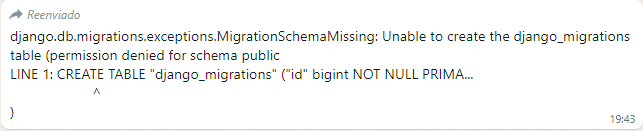
Un año un poco pesado en el trabajo pero aquí una nueva entrada al blog:
Instalar Manualmente Red Hat Process Automation Manager (RHPAM) 7.13 en Rocky Linux 9.3 (Blue Onyx).
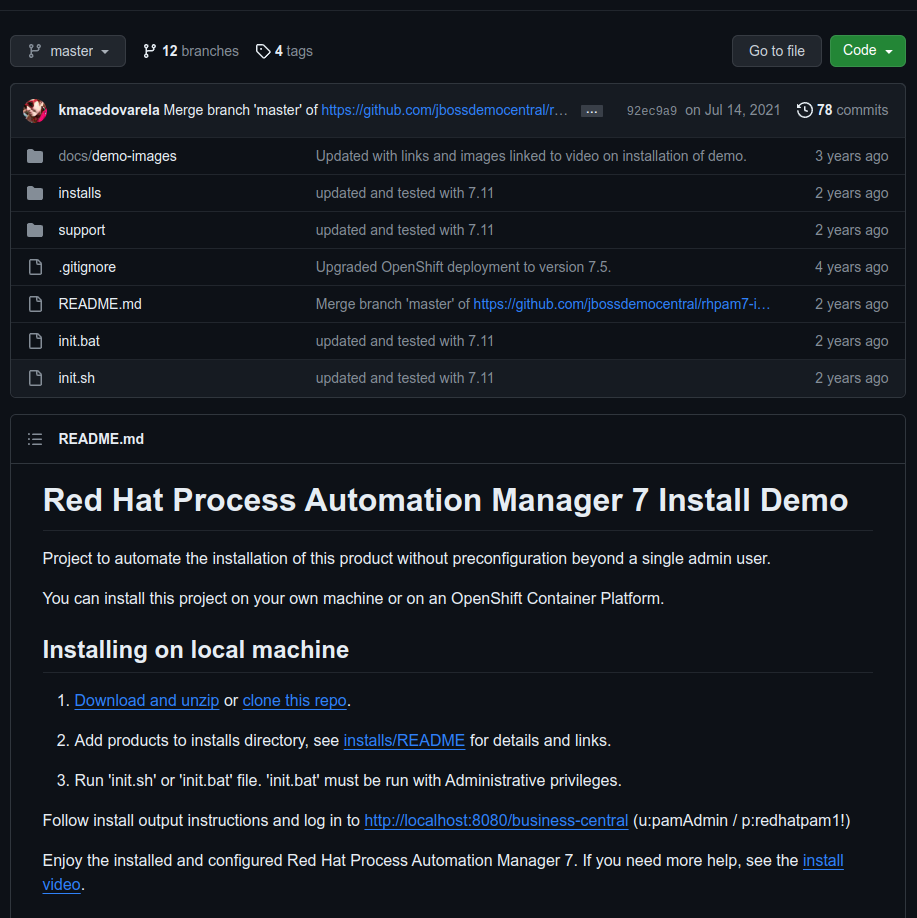
Me encargaron instalar este software de Red Hat en un servidor Rocky Linux 9.3 así que me puse a investigar la forma más sencilla de instalarlo. Buscando por la internet me encontre con este sitio en GitHub:
https://github.com/jbossdemocentral/rhpam7-install-demo.
En él, el autor nos proporciona una forma automatizada de hacer la instalación del software RHPAM version 7.11 así que seguiremos la guía que ahí se publica haciendo algunos pequeños cambios al script. En el sitio se indica como hacer la instalación tanto en una máquina local como sobre Openshift. Me centraré en la instalación en una máquina local. Este software fue desarrollado en lenguaje Java por lo que es necesario instalar antes la version 11 (en el manual de instalación dice que se puede usar con la versión 8 u 11 de java, sin embargo con la versión 8 marca errores ). Si no tienes instalado java lo puedes hacer ejecutando el siguiente comando con permisos de administrador:
sudo dnf install java-11-openjdk
Siguiendo las instrucciones que se indican, podemos bajar el zip del proyecto o clonarlo en una carpeta de su preferencia. Si se descarga el zip, una vez descomprimido haremos los siguientes cambios:
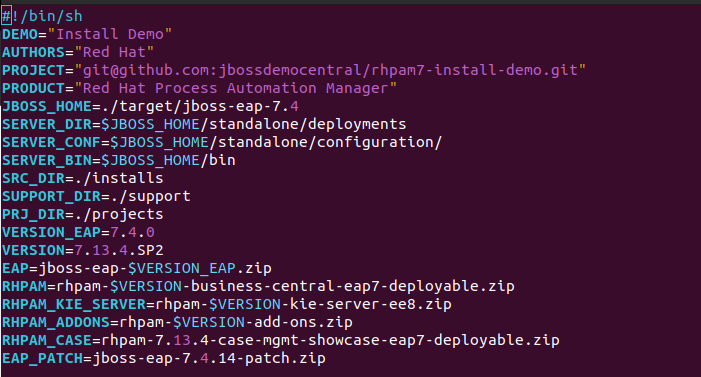
Descarga el archivo soporte.zip y descomprímelo; contiene los archivos init.sh y standalone-full.xml. Copia init.sh a la carpeta raíz del proyecto, reemplazando el original (o si quieres respaldarlo antes) y el archivo standalone-full.xml cópialo en la carpeta support reemplazando también el original. El inicio archivo init.sh debe iniciar con algo como esto:
Descarga los 5 productos que se muestran a continuación y colócalos en la carpeta installs:
jboss-eap-7.4.0.zip, jboss-eap-7.4.14-patch.zip, rhpam-7.13.4.SP2-add-ons.zip , rhpam-7.13.4.SP2-business-central-eap7-deployable.zip y rhpam-7.13.4.SP2-kie-server-ee8.zip.
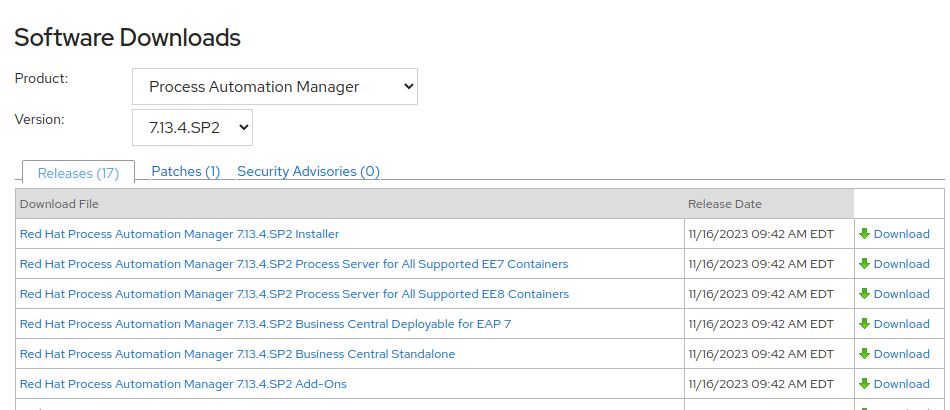
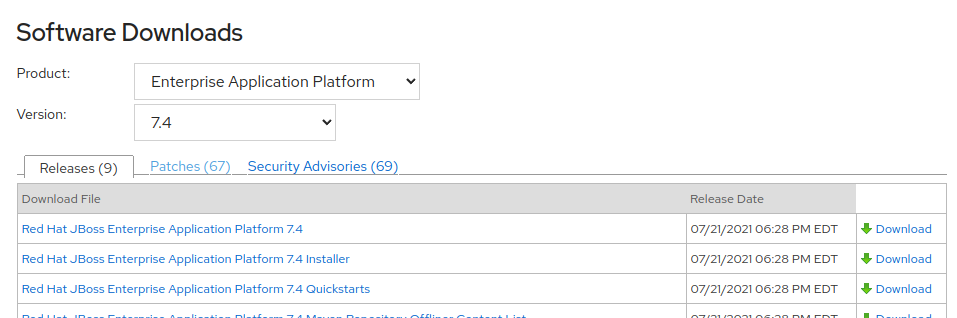
Dichos productos los puedes encontrar en el sitio de descargas del software Red Hat Process Autamtion Manager, para ello necesitas estar registrado en el sitio. Un fragmento de la página se verá así:
La última versión al tiempo de escribir el artículo es la 7.13.4.SP2. Descárgate los archivos siguientes que corresponden a lo súltimos tres listados más arriba:
Red Hat Process Automation Manager 7.13.4.SP2 Process Server for All Supported EE8 Containers, Red Hat Process Automation Manager 7.13.4.SP2 Business Central Deployable for EAP 7 y Red Hat Process Automation Manager 7.13.4.SP2 Add-Ons.
En la misma página de descargas, selecciona del menú de la izquierda el link Enterprise Application Platform para que aparezcan las descargas de este software. Selecciona la última version no Beta. En este tiempo es la versión 7.4 y descarga el software Red Hat JBoss Enterprise Application Platform 7.4. En la misma página, de la sección “Patches”, descárgate el software de actualización Red Hat JBoss Enterprise Application Platform 7.4 Update 14 . Los nombres de los archivos zip descargados deben de corresponder a los primeros dos de la lista más arriba.
Una vez descargados los cinco archivos agrégale el permiso de ejecución a cada uno de ellos con el comando
chmod +x <carpeta-del-proyecto/installs/<nombre-archivo-zip>
Ejecuta el archivo init.sh que se encuentra en la carpeta raíz del proyecto de la siguiente forma (recuerda tener instalado java 11 y que sea la versión por defecto):
./init.sh
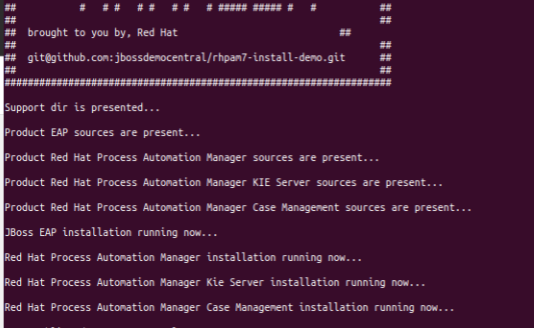
Si todo va bien el comando mostrará algo como esto:
Al final mostrará como ejecutar el software RHPMA y los usuarios y passwords creados para acceder a él. Si ejecutamos tal como dice la imagen, sólo tendremos acceso desde la misma máquina donde se instaló.
Para acceder desde otro equipo en la red será necesario ejecutar el comando de la siguiente forma para iniciar la aplicación:
./target/jboss-eap-7.4/bin/standalone.sh -b 0.0.0.0 -bmanagement 0.0.0.0
Y para acceder desde un navegador tenemos que usar el puerto seguro 8443 ya que si usamos el puerto 8080 el navegador, por seguridad, no permitirá acceder a la aplicación, así:
https://<IP o NOMBRE-HOST>:8443/business-central/
el navegador mandara una alerta de seguridad yaq ue no contamos con un certificado válido, podemos ignrorar la alerta y acceder de todos modos cuando nos pregunte. Si todo esta correcto, nos mostrará la pantalla principal de la aplicación:
Accedemos con algún que se mostraron en la pantalla que arrojó el script. Por ejemplo con el usuario administrador pamAdmin y nos aparecerá la ventana del administrador:
Espero y les sea útil. ¡Hasta pronto!